First-Generation AI Scribes Are Lying to Your Physicians.
Hallucinated diagnoses. Fabricated findings. Patient words twisted into medical jargon they never said. The industry calls it "acceptable error rates." We call it unacceptable.
Last updated: February 2026
A 2025 study from Mount Sinai found that when large language models encounter erroneous clinical input, they don't flag the error—they elaborate on it in up to 83% of cases.
This isn't a bug. It's an architectural inevitability of single-prompt AI systems that try to do everything at once—listen, understand, extract, interpret, and generate—all in one pass.
What Does the Research Say About AI Scribe Safety?
We didn't discover these problems through marketing research. We found them in peer-reviewed clinical literature—the same studies that should have stopped the industry from shipping.
Peer-Reviewed ResearchThe 1-3% Figure Is Misleading
Vendors cite "1-3% hallucination rates" from controlled studies. But that's under ideal conditions—clean audio, single speaker, straightforward cases. Real emergency departments have overlapping speakers, background noise, patients who contradict themselves, and interpreters.
The Mount Sinai study tested what happens when AI encounters the kind of imperfect input that's inevitable in clinical practice. The result: hallucination rates climbed to 50-83% depending on the model.
What Are the 5 Failure Modes of First-Generation AI Scribes?
Clinical research has identified systematic failure patterns in first-generation ambient AI. These aren't edge cases—they're architectural inevitabilities of single-pass systems.
AI systems fabricate clinical content that was never discussed. A 2024 study found GPT-4o produced incorrect or overly generalized information in 42% of medical note summaries.
"I got dizzy going up the stairs"
"Syncopal episode. Recommend cardiac workup and orthostatic vitals."
When patients say 'waves,' AI writes 'colicky.' When they say 'sweating,' AI writes 'diaphoresis.' This isn't translation—it's interpretation. Medical terminology implies clinical judgment the AI isn't qualified to make.
"The pain comes and goes in waves"
"Intermittent, colicky abdominal pain"
Research shows 66-87% of clinical notes contain hedge phrases expressing uncertainty. AI systems systematically strip this uncertainty, presenting confident facts where patients gave hesitant possibilities.
"I might be allergic to penicillin—my mom told me I had a reaction as a baby"
(nothing—allergy dropped entirely)
Real patients contradict themselves. 'No chest pain.' Then later: 'Maybe a little tightness.' First-generation AI picks one answer—usually the first—hiding diagnostic ambiguity your physicians need to see.
"No, not really... well, maybe a little pressure"
"Denies chest pain"
When extraction fails, you can't debug it. Single-prompt architectures offer no audit trail, no stage-by-stage verification. Standard NLP metrics 'correlate poorly with clinical relevance, factual correctness, or patient safety.'
"(Complex multi-speaker trauma encounter)"
(Unknown source of errors, no traceability)
Who Is Liable When AI Documentation Fails?
Most AI scribes operate without FDA oversight, classified as "administrative tools" rather than medical devices. This creates a regulatory gap where vendors face no accountability for documentation errors.
"The legal doctrine of respondeat superior holds the healthcare provider responsible for the accuracy of the medical record, regardless of whether it was generated by a human or an AI scribe."
— Texas Medical Liability Trust, Risk Management Considerations
Documentation errors don't just affect patient care—they weaken legal defensibility. According to malpractice insurers, "some cases with good medicine are settled because of poor documentation" and "jurors may believe documentation rife with errors indicates a lack of attention to detail."
Scale of Adoption
7,000+ physicians
One healthcare system reported 2.5 million AI-documented encounters in 14 months
Validation Gap
66%
of physicians now use AI tools at work—a 78% increase from 2023 (AMA, 2024)
Adoption is outpacing validation. Organizations are deploying AI scribes at scale without the safety infrastructure to catch errors before they reach patient records.
What Is PRISM Architecture?
A fundamentally different architecture built on one principle: separate what should never be conflated.
PRISM isn't a better prompt. It's a better architecture. Research on multi-stage AI systems shows that "higher layers handling goal setting and task decomposition, while lower layers focus on execution... reduces error propagation." PRISM applies this principle to clinical documentation.
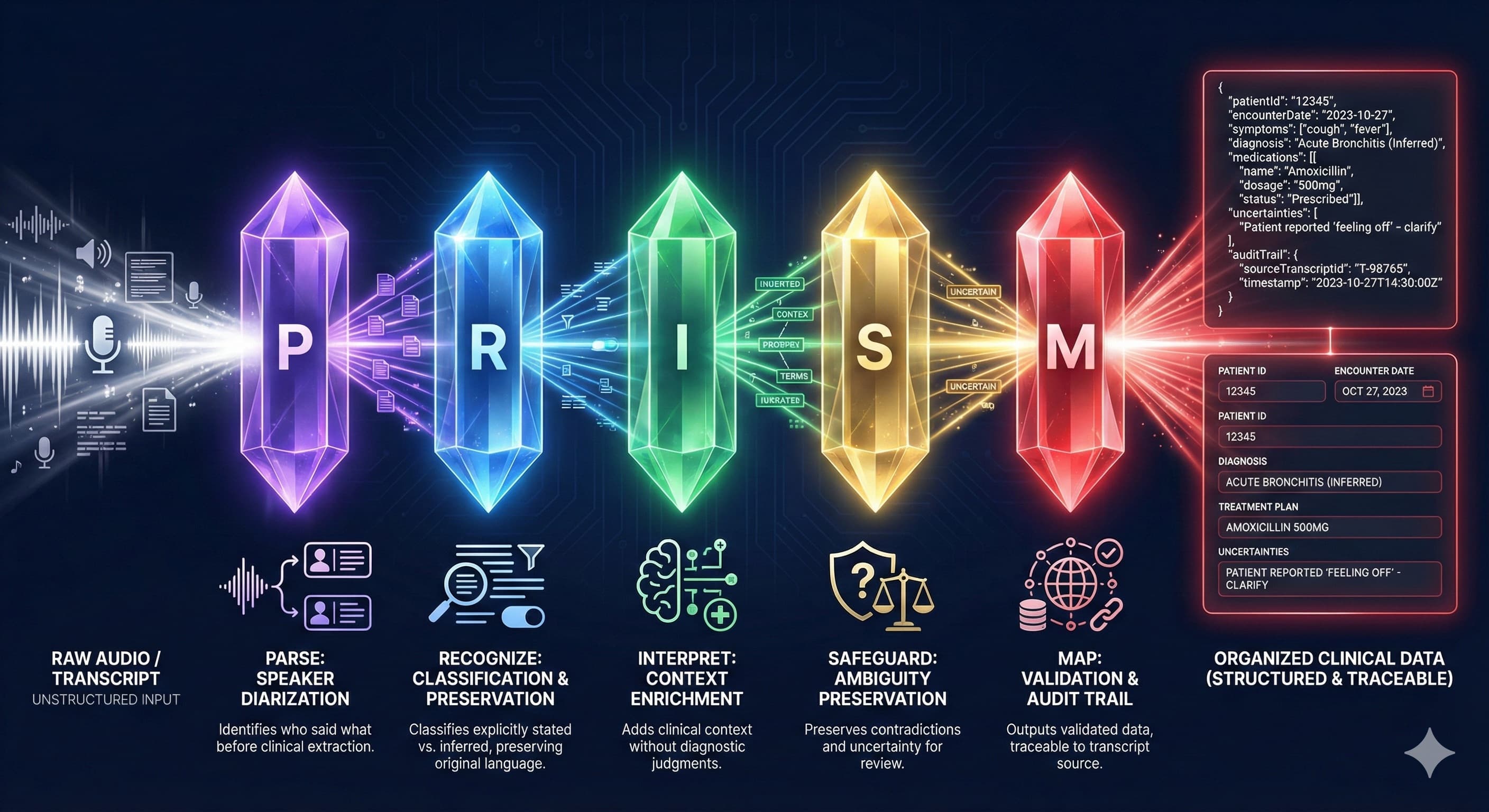
Five stages. Five responsibilities. Zero interference. Each stage receives input only from the previous stage, preventing the catastrophic interference that plagues single-pass systems.
How Does PRISM's 5-Stage Pipeline Work?
Each stage has exactly one job—and explicit architectural constraints against overstepping. This isn't prompt engineering. It's system design.
Structural organization only
Speaker attribution. Interruption handling. Semantic segmentation. Determines who said what and where topics begin and end. No clinical interpretation—just structure.
Data extraction with provenance
Identifies clinical data elements with explicit vs. inferred classification. Tags each extraction as 'patient stated' or 'inferred from context.'
Context enrichment only
Emergency medicine-specific pattern recognition. Identifies acuity signals, mechanism chains, temporal relationships. Context without clinical judgment.
Validation and audit
Assigns confidence levels. Preserves contradictions rather than resolving them. Traces every output to transcript source. Flags uncertainty for physician review.
Output generation only
Transforms validated, interpreted data into structured clinical documentation. The final assembly stage that outputs only what upstream stages have verified.
When your physicians review a PRISM extraction, they see exactly what the patient said—not what an AI thinks they meant. Every data element traces back to its source. Every uncertainty is preserved.
How Is PRISM Validated for Clinical Safety?
We didn't hope PRISM would work. We proved it using methodologies derived from both software engineering and clinical safety research.
The RWE-LLM framework—which engaged 6,200+ US licensed clinicians across 307,000+ clinical interactions—established that effective AI validation requires "structured severity classifications for identified issues rather than binary pass/fail assessments." We adopted this principle.
Adversarial Scenario Testing
Following the CARES benchmark methodology—which tests "harmful content, jailbreak vulnerability, and false positive refusals"—we designed test scenarios for each documented failure mode.
| Scenario | Challenge | Result |
|---|---|---|
| Pediatric | Parent speaks for child | 94% |
| Psychiatric | Disorganized speech | 100% |
| Trauma | Multiple speakers | 87% |
| Interpreter | Three-way translation | 89% |
| Geriatric | Unreliable historian | 92% |
| Contradictory | Patient changes story | 100% |
| Planted Error | Mount Sinai methodology | 100% |
Multi-Model Validation
Research indicates that "single-model deployments are deemed insufficient" for clinical safety. PRISM was validated across three AI models with dramatically different capabilities.
Architecture-Enforced Reliability
We've layered machine learning and open-source tools and datasets from MIT on top of the latest LLM models to validate an architecture that enforces correctness regardless of the underlying AI. When the next generation of model arrives, the PRISM engine is ready.
Why Choose PRISM Over First-Generation AI Scribes?
You can deploy AI scribes that hallucinate under pressure, strip uncertainty from patient statements, and leave you liable for errors you can't trace. Or you can use documentation technology that was engineered for medicine from the ground up.
PRISM isn't just different. It's what different was always supposed to mean.
Research Citations
Mount Sinai (2025). Multi-model assurance analysis showing large language models are highly vulnerable to adversarial hallucination attacks. Communications Medicine.
Shing et al. (2025). A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation. npj Digital Medicine.
Hanauer et al. (2012). Hedging their Mets: The Use of Uncertainty Terms in Clinical Documents. AMIA Annual Symposium Proceedings.
PMC (2025). Beyond human ears: navigating the uncharted risks of AI scribes in clinical practice.
Texas Medical Liability Trust. Using AI medical scribes: Risk management considerations.
JAMA Network Open (2024). Physician Perspectives on Ambient AI Scribes.